


"Google Knowledge Graph" Uzlaşdırması Və Əsas Vahidi
“Google Knowledge Graph” insanlar, yerlər, obyektlər, anlayışlar və bunlar arasındakı əlaqələr kimi müxtəlif "varlıqları" ehtiva edən verilənlər bazasıdır. O, internetdəki geniş məlumat fondundan dəqiq və müvafiq məlumatları seçərək “Google” axtarış nəticələrini zəngin və kontekstli edir.
“Google Knowledge Graph Reconciliation”
“Google”un bilik qrafiklərinin uzlaşdırılması internetdən əldə edilən bilik kitabxanalarının tamamlanması və gücləndirilməsi prosesidir. Bu prosesin əsas əhəmiyyəti “Knowledge Graph”da çatışmayan saytların və bu saytlar arasındakı əlaqələr zamanı aşkarlanan boşluqların doldurulmasıdır. Bəs bu nə deməkdir? Gəlin onu aydınlaşdıraq.
Məsələn, “Google”un bilik qrafikində müəllif və onun əsərləri arasındakı əlaqə mövcud olsa da, müəllifin son əsərləri həmin cədvələ əlavə edilməyə bilər. “Reconciliation” prosesi belə çatışmazlıqları aşkar edir. Daha sonra bu boşluqları etibarlı mənbələrdən (məsələn, nəşriyyat məlumat bazaları, akademik jurnallar və ya cari xəbər saytları) toplanmış məlumatlarla doldurur.
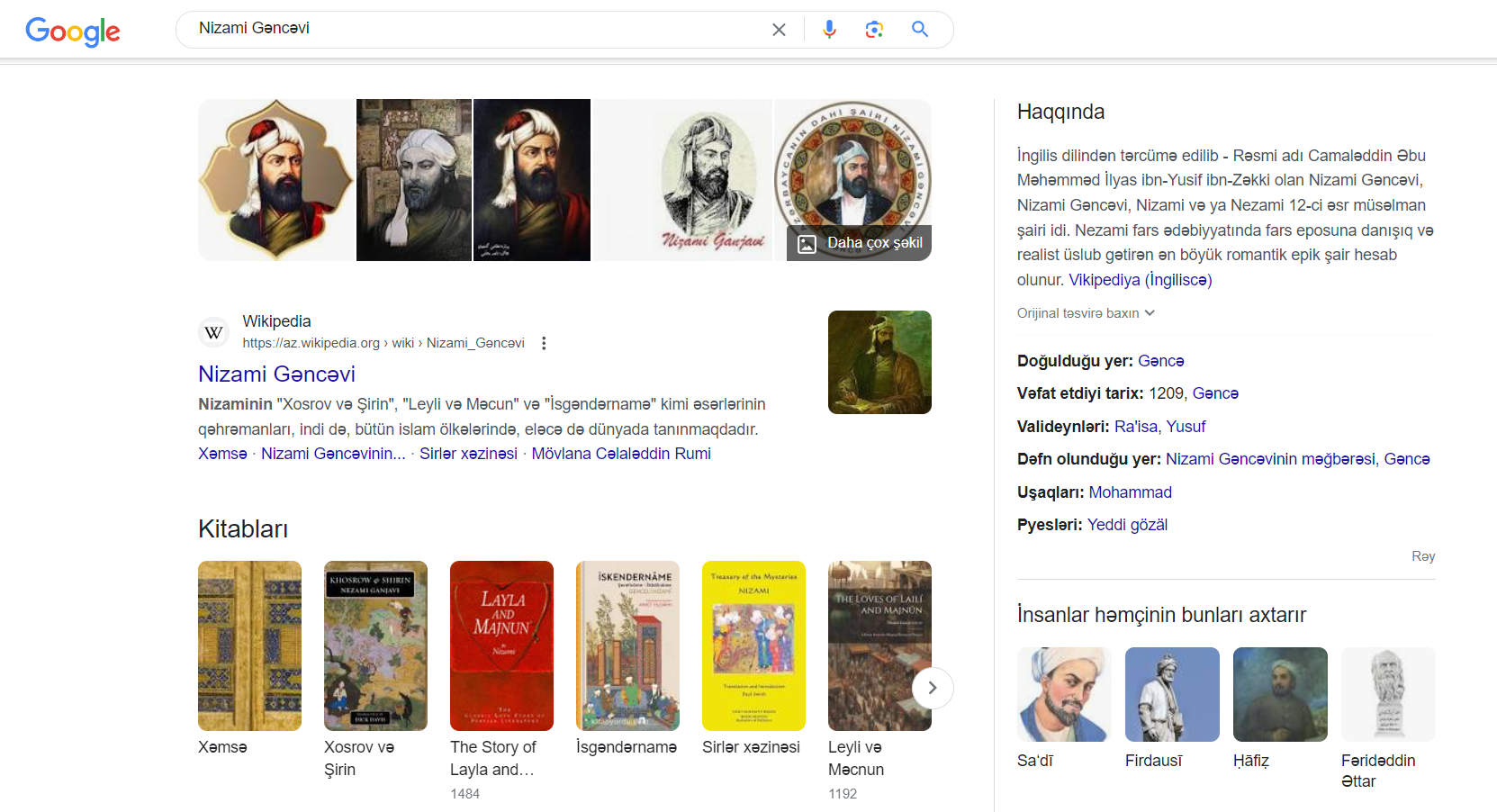
Bu prosesin daha bir üstünlüyü onun ki, sistem nəinki yeni məlumatlar əlavə edir, həm də mövcud məlumatların düzgünlüyünü də daim yoxlayır. Tutaq ki, bir şəhər haqqında demoqrafik məlumatlar tez-tez dəyişir və ya tarixi hadisələr nəticəsində yeni məlumatlar ortaya çıxır. Uzlaşma bu cür yeniləmələri izləyir və “Google”un bilik qrafikində əks etdirir.
Bilik qrafikinin əsas vahidləri: Tuples
Bilik qrafikində 'tuple' adlanan əsas vahidlər varlıq (mövzu) ilə bu varlıq haqqında fakt (predikat/obyekt cütü) arasındakı əlaqəni ifadə edir.
“Google Knowledge Graph”da hər bir tuple iki əsas komponentdən ibarətdir:
1.Obyekt
2.Həmin obyekt haqqında fakt
Bu ikili struktura obyekt və subyektlə əlaqəli mühakimə daxildir. Məsələn, "Bakı" (obyekt) və "Azərbaycanın paytaxtıdır" (subyekt) bir dəst təşkil edir. Bu sadə struktur məlumatı asan və başa düşülən edir.
Bilik qrafikində dəstlər müxtəlif obyektləri birləşdirir. Bu varlıqlar insanlar, yerlər, obyektlər və ya anlayışlar ola bilərki, struktur bu varlıqlar arasındakı əlaqələri göstərir. Məsələn, “Bakı” və “Azərbaycan” arasındakı “paytaxt” münasibəti bu iki varlığı birləşdirən bir dəst kimi düşünülə bilər.
Dəstlər bu amillərə əsasən qruplaşdırılır:
- Mənbə
- Subyektin növü
- Subyektin adı
Qeyd edim ki, tuples yalnız obyektləri və faktları ehtiva etmir, həm də əlavə məlumat verə bilər:
- Kontekst məlumatı. Tuplenin mənasını zənginləşdirən əlavə məlumat.
- Statistik məlumat. Müəssisələr və əlaqələr haqqında kəmiyyət məlumatı.
- Nəzarət məlumatı. Tuplenin mənbəyi və etibarlılığı haqqında məlumat.
- Kənarlar haqqında metadata. Müəssisələr arasında əlaqələrin xüsusiyyətləri.
“Google Knowledge Graph Reconciliation” patent prosesi:
1.Məlumatların toplanması və təhlili
Veb əsaslı mənbələrdən əldə edilən məlumatlara potensial aktivlər və həmin aktivlər haqqında faktlar daxildir. Bu faktlar əldə edildikdən sonra təhlil edilir və təmizlənərək ən vacib olanlar seçilir. Daha sonra mənbələri təmsil edən kiçik miqyaslı məlumat qrafikləri yaradılır.
2.Mənbə qrafiklərinin yaradılması
Hər bir mənbə dəsti üçün ayrıca mənbə məlumat qrafikləri hazırlanır. Bu diaqramlarda hələ hədəf məlumat diaqramına daxil edilməyən yeni obyektlər ola bilər.
3.Klasterləşmə və təsnifat
Sistem mənbə məlumat qrafiklərini mənbə obyektinin növü və adına əsasən təsnif edir. Müəssisə adları mənbə mətndən çıxarılan məlumatla müəyyən edilir.
4.Dəstlərə ayrılma və yoxlama
Sistem obyektləri və əlaqələri ehtiva edən qrafikləri xüsusi xüsusiyyətlərə əsaslanaraq dəstərə ayırır. Deterministik mülahizələrdən istifadə edərək, bu dəstləri daha da xüsusi alt qruplara bölmək olar.
5.Etibarlılığın qiymətləndirilməsi
Qeyri-kafi etibarlılıq və ziddiyyətli məlumatlar olan qəstlər aradan qaldırılır. Qalan etibarlı məlumatlar isə əlavə təhlil üçün birləşdirilir.
6.Hədəf məlumat qrafikinə inteqrasiya
Birləşdirilmiş məlumatlar yeni obyektlər və onlar üçün yeni faktları hədəf məlumat qrafikinə əlavə etmək üçün istifadə olunur. Bu proses həm əhatə dairəsini genişləndirir, həm də bilik qrafikinin dəqiqliyini artırır.
“Google Knowledge Graph Reconciliation”un bu addımları internetə olan məlumat axınına uymaq üçün davamlıdır, yəni daim yenilənir. Bu davamlı yenilənmələr sayəsində istifadəçiləri daha dəqiq və əhatəli məlumatlarla təmin edir.
Tərs tuples nədir?
“Google Knowledge Graph”ın maraqlı xüsusiyyətlərindən biri onun tərs dəstlər yaratması və lazım olduqda onu ləvğ etməsidir. Məlumatların daha dəqiq və yenilənməsinə kömək edən bu prosesin gedişatı belədir:
Tərs dəstələrin yaradılması
Tuple subyekt-feil-obyekt formatında olduqda, bunun əksi olan dəst yaradıla bilər. Məsələn:
Orijinal tuble: "Bakı Azərbaycanın paytaxtıdır."
Tərs tuple: "Azərbaycanın Bakı adlı şəhəri var və həmin şəhər oranın paytaxtıdır."
Bu, müxtəlif perspektivlərdən məlumat təqdim etməklə bilik qrafikini daha əhatəli edir.
Ziddiyyətli tuples ilə işləmək
Bəzən müxtəlif mənbələrdən olan dəstələr ziddiyyət təşkil edə bilər. Məsələn, hər hansısa futbolçu, Mahir Emreli haqqında axtarış edilibsə, bu nəticələr ola bilər:
Tuple # 1: "Azərbaycanın Mahir Emreli adlı futbolçusu var."
Tuple # 2: "Mahir Emreli Dinamo klubu oyunçusudur."
Bu iki dəst ziddiyyət təşkil etdikdə, bilik qrafikinin uzlaşdırılması zamanı onlardan biri ləğv edilə bilər.
Tuples etibar həddi
Hər bir tuple üçün müəyyən bir etibarlılıq həddi var. Bu həddə cavab verməyən dəstlərin kifayət qədər etibarlılğı olmadığı halda ləvğ ediləcək.
Məsələn, tək bir mənbədən olan tuple etibarsız sayılıb ləğv edilə bilər. Eynilə, eyni domenlə əlaqəli üç mənbədən alınan bir dəst kifayət qədər dəqiq hesab olunmadığı üçün ləvğ ola bilər.
“Google Knowledge Graph Reconciliation” patentinin üstünlükləri:
- Sürətli genişlənmə. Sənəddəki obyektləri və onlar haqqında faktları qısa müddətdə müəyyən etməklə, məlumat qrafiki daha tez genişləndirilir.
- Yüksək keyfiyyətli məlumat. Diaqramın təsdiqləmə prosesi sayəsində əldə edilən aktivlər və faktlar yüksək keyfiyyətlidir.
- Müxtəlif mənbələrdən məlumatların toplanması. Müəyyən edilmiş obyektlər xəbər mənbələrindən götürülür və məlumat qrafikinə yeni obyektlər əlavə edilir.
- Böyük miqyaslı məlumat axını. Potensial yeni obyektlər və faktlar minlərlə və ya yüz minlərlə mənbədən əldə edilir.
- Daha dəqiq axtarış nəticələri. Məlumat qrafikinə əlavə edilən obyektlər və faktlar axtarış nəticələrini daha əhatəli və dəqiq edir.


.jpg)